

(10 June 2026)
 New paper Geriatric Syndromes Extraction from Discharge Summaries - A New Dataset, Annotation Scheme and Initial Findings published in Frontiers in Digital Health. https://www.frontiersin.org/journals/digital-health/articles/10.3389/fdgth.2026.1591050/.
New paper Geriatric Syndromes Extraction from Discharge Summaries - A New Dataset, Annotation Scheme and Initial Findings published in Frontiers in Digital Health. https://www.frontiersin.org/journals/digital-health/articles/10.3389/fdgth.2026.1591050/.
Geriatric syndromes (GS), such as falls, dementia, delirium and malnutrition, are complex clinical conditions affecting older adults which involve multiple organ systems and have major impact on quality of life and care. GS cut across disease categories, and are poorly represented in structured electronic health records. Natural language processing (NLP) offers an opportunity to extract valuable GS-related information from unstructured clinical text, such as hospital discharge summaries. However, the lack of high-quality annotated datasets limits the effectiveness of NLP models in this domain. This study introduces a manually annotated corpus designed for GS detection, enabling more accurate identification and classification of GS. Our evaluation showed that, for the document-level labelling task, BERT-cased achieved the highest F1-score (0.897) and BioClinicalBERT performed best when negation was considered (F1-score 0.888). For the NER task, BioClinicalBERT and BERT-cased achieved an F1-score of 0.883. Frailty (F1=1.0), Falls (F1=0.973) and Delirium (F1=0.946) are the GS entities with the best performing results. For NER-C, BERT-cased achieved the best F1 of 0.692 and BioBERT performed the worst (F1=0.658). In NER-C, the best results were achieved for context-aware falls and frailty labels, particularly when the syndrome was implied rather than explicitly stated. Document-level aggregation helped reduce inconsistencies, but the NER experiments used a flattened CoNLL-compatible representation of the original annotations, in which discontinuous mentions were converted into shortest covering spans and overlapping mentions were merged. Therefore, the reported NER results should be interpreted as baseline performance on a simplified representation of these structures, while low-frequency GS categories and sparse contextual labels also negatively affected model accuracy.
Read it at https://www.frontiersin.org/journals/digital-health/articles/10.3389/fdgth.2026.1591050/.
(9 June 2026)
 New paper A large dataset of brain imaging linked to health systems data - curation and access to a whole system national cohort from NHS Scotland published in GigaScience. DOI:10.1093/gigascience/giag072.
New paper A large dataset of brain imaging linked to health systems data - curation and access to a whole system national cohort from NHS Scotland published in GigaScience. DOI:10.1093/gigascience/giag072.
We present the design and implementation of a data curation framework to generate a large-scale clinical brain imaging dataset suitable for artificial intelligence (AI) enabled image analysis. The dataset is accessible through the Brain Health Data (BHD) initiative, which includes approximately 417,341 magnetic resonance imaging (MRI) and 846,077 computerized tomography (CT) head studies, linked electronic health records (EHRs), and associated free-text imaging reports from clinical practice between 2010 and 2018 in Scotland, exceeding 185 TB in size. The data curation framework was developed during the SCottish AI in Neuroimaging to predict Dementia and Neurodegenerative Disease (SCANDAN) study, which used a subset of 41,966 MRI series from the BHD for dementia prediction. We describe the processing of the BHD metadata and our multilabel classification output. We discuss the strengths of the BHD, including clinical relevance thanks to its unprecedented scale, population-wide representativeness of a national free-at-the-point-of-delivery healthcare, long-term follow-up to neurodegenerative disease, and real-world variability. We describe the challenges and lessons learnt in developing a framework to curate data, including the time needed to obtain permissions, the need for easily accessible, secure, responsive and affordable computational environments, the variability of clinical data, and the challenge of extracting linked clinical data and images at scale. This resource will be crucial for clinical research, fostering the development of personalized medicine approaches, and fast-tracking the implementation of AI models in clinical workflows. We encourage the use of the BHD data through a streamlined application to the Public Benefit and Privacy Panel for Health and Care via the Data Research and Innovation Service of Public Health Scotland (eDRIS).
Read it at DOI:10.1093/gigascience/giag072.
(6 June 2026)
 New Protocol Observational study of predictors and outcomes of lung cancer in never-smokers in the UK (OLIVE) - study protocol published in BMJ Open Respiratory Research. DOI:10.1136/bmjresp-2025-003966.
New Protocol Observational study of predictors and outcomes of lung cancer in never-smokers in the UK (OLIVE) - study protocol published in BMJ Open Respiratory Research. DOI:10.1136/bmjresp-2025-003966.
Lung cancer is commonly associated with smoking. However, if considered separately, lung cancer in never-smokers (LCINS) is the seventh most common cause of cancer-related death worldwide. Expanding the limited understanding of LCINS, especially in the UK, is crucial to improving diagnosis. We will establish a retrospective and prospective UK multicentre observational cohort comprising never-smoking (lifetime use of <100 tobacco cigarettes) adults with lung cancer using routinely available primary and secondary care electronic health records (EHRs). Demographic data including occupation and ethnicity, exposures and lung cancer outcomes will be extracted. Deep learning-based natural language processing will be used to analyse free-text data. Quantitative or qualitative data collection for information not available in EHR may be initiated in the future. Follow-up will be until death, withdrawal or end of study (5 years from study activation date). Primary outcomes will be sociodemographic characteristics, comorbidities, environmental exposures, pathways to presentation and symptoms. A feasibility pilot of 225 patients (25 participants per year both retrospectively and prospectively) will be undertaken at one hospital before extending the study to multiple sites. Patient representatives have been involved in adapting the research protocol including the recruitment process and patient-facing materials.
Read it at DOI:10.1136/bmjresp-2025-003966.
(27 May 2026)
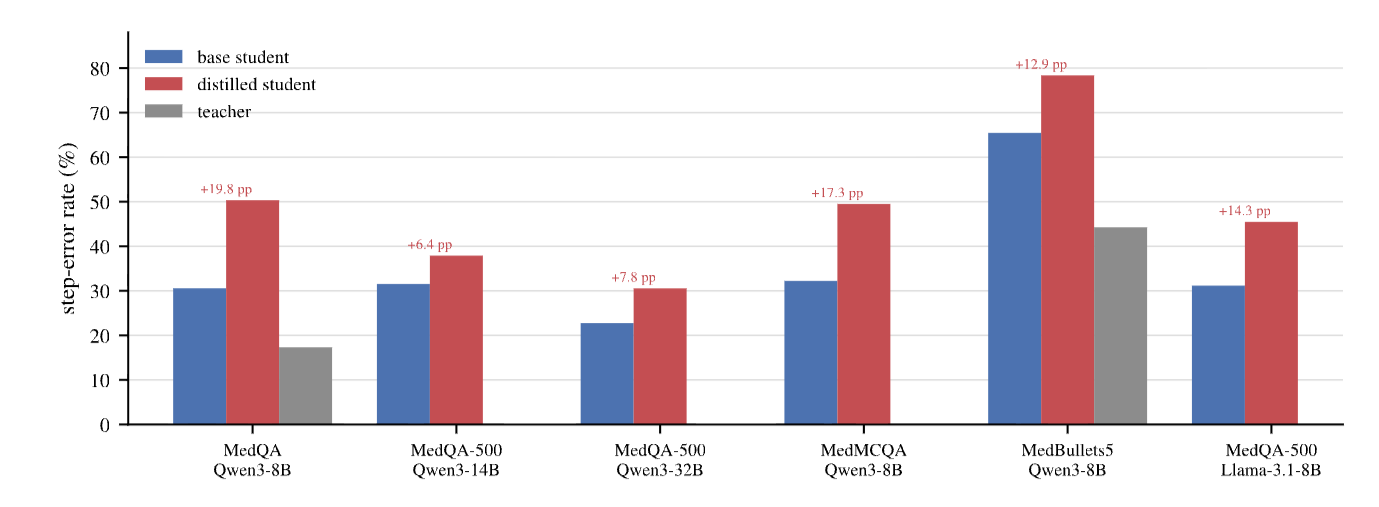 New Preprint Better Accuracies, Worse Reasoning - A Step-Level Audit of Medical Chain-of-Thought Distillation at arXiv:2605.28301.
New Preprint Better Accuracies, Worse Reasoning - A Step-Level Audit of Medical Chain-of-Thought Distillation at arXiv:2605.28301.
Chain-of-thought (CoT) distillation trains a smaller model to imitate a teacher’s reasoning trace, but it is typically evaluated by final-answer metrics including accuracy. We ask whether gains in answer quality are accompanied by improvements in the trace. In medical QA, where short answer options can leave a richer clinical justification under-specified, a Qwen3-8B student distilled from a DeepSeek-V3-family teacher improves on MedQA-USMLE answer metrics (SC@64 74.7% to 84.4%; expected calibration error (ECE) 0.096 to 0.034). Yet under a Kimi-K2.6 style-blind LLM-judge audit, its error rate over non-abstained steps rises from 30.6% to 50.3%. In this primary medical setting, answer quality and trace factuality move in opposite directions. This before–after pattern persists across evaluators, teacher strengths, student scales and families, medical benchmarks, and style, segmentation, and answer-correctness controls. A 150-step blinded audit by a clinical expert reproduces the same ordering. Boundary checks narrow the scope of the claim - the risk appears when a compact answer under-constrains the rationale and a capable student can imitate expert-like form without reliably grounding each local claim. Standard answer metrics and aggregate hedging rates do not reveal the shift. When such traces are released or reused, answer-level metrics alone are insufficient.
Read it at arXiv:2605.28301.
(8 May 2026)
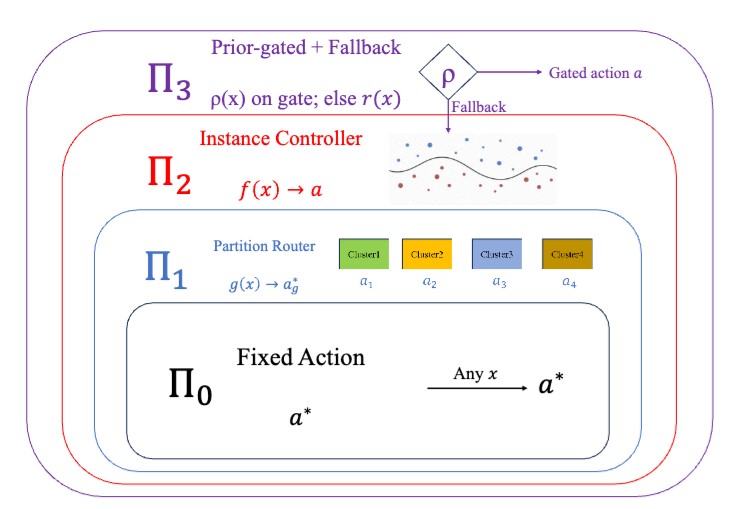 New Preprint A Regime Theory of Controller Class Selection for LLM Action Decisions at arXiv:2605.06339.
New Preprint A Regime Theory of Controller Class Selection for LLM Action Decisions at arXiv:2605.06339.
Deployed language and vision-language models must decide, on each input, whether to answer directly, retrieve evidence, defer to a stronger model, or abstain. Contrary to the common monotonicity intuition, greater per-input expressivity is not uniformly beneficial in finite samples - under identical strict cross-validation, different benchmarks prefer different controller classes. This reflects a finite-sample limitation of instance-level uncertainty signals, which can be exhausted at a distribution-dependent scale. We organize controllers into a nested lattice of four classes - fixed actions, partition routers, instance-level controllers, and prior-gated controllers, ordered by complexity. We prove a regime theory that turns three data-estimable bottlenecks into a class choice - how much improvement is possible beyond the best fixed action, whether there are enough samples for instance-level controllers to make reliable decisions, and how much improvement a coarse partition router can recover when instance-level signal is unreliable. The resulting Bernstein-tight threshold has a matching information-theoretic lower bound, and strict nested cross-validation provably selects a near-best class. Across SMS-Spam, HallusionBench, A-OKVQA, and FOLIO, the predicted class matches the empirical winner; the prior-gated controller wins on TextVQA when OCR tokens supply a label-free prediction-time prior.
Read it at arXiv:2605.06339.
(8 May 2026)
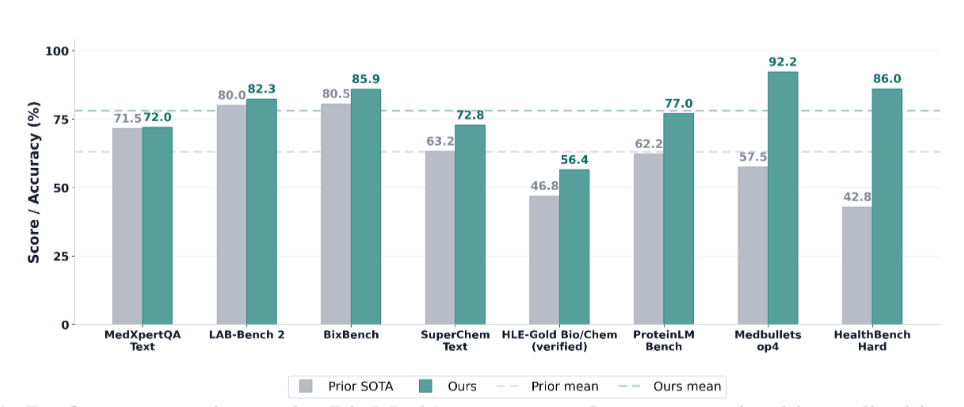 New Preprint BioMedArena - An Open-source Toolkit for Building and Evaluating Biomedical Deep Research Agents at arXiv:2605.06177.
New Preprint BioMedArena - An Open-source Toolkit for Building and Evaluating Biomedical Deep Research Agents at arXiv:2605.06177.
Building a deep research agent today is an exercise in glue code - the same backbone evaluated on the same benchmark can report different accuracies in different papers because harness and tool registry all differ, and integrating a new foundation model into a comparable evaluation surface costs weeks of model-specific engineering. We call this the per-paper engineering tax and release BioMedArena, an open-source toolkit that not only alleviates it but also provides an arena for fair comparison of different foundation models when evaluating them as deep-research agents. BioMedArena decouples six layers of biomedical agent evaluation – benchmark loading, tool exposure, tool selection, execution mode, context management, and scoring – and exposes 147 biomedical benchmarks and 75 biomedical tools across 9 functional families. Adding a new model, benchmark, or tool reduces to registering a few-line provider adapter. We further provide 6 agent harnesses with 6 context-management strategies, which provide 12 backbones with competitive research capabilities and significantly improved performance, achieving state-of-the-art (SOTA) results on 8 representative biomedical benchmarks, with an average lift of +15.03 percentage points over prior SOTA.
Read it at arXiv:2605.06177.
(23 March 2026)
 Paper published on Frontiers in Endocrinology External validation and application of a machine learning–based model for diabetes progression in prediabetes at DOI:10.3389/fendo.2026.1746570.
Paper published on Frontiers in Endocrinology External validation and application of a machine learning–based model for diabetes progression in prediabetes at DOI:10.3389/fendo.2026.1746570.
This study externally validated a machine learning–based model for type 2 diabetes progression (ML-PR) and evaluated its clinical utility in individuals with prediabetes. We included 3,081 participants from the Diabetes Prevention Program (DPP) and the DPP Outcome Study (DPPOS). The ML-PR model was assessed using dicrimination, calibration curves, and decision curve analysis, and its performance was compared with existing diabetes prediction models. Based on ML-PR scores, patients were stratified into high- or low-risk categories. Cox proportional hazards and logistic regression models were used to evaluate the incidence of type 2 diabetes, microvascular complications, and cardiovascular events across risk and intervention groups. The ML-PR model achieved an area under the ROC curve of 0.74 (95% confidence interval 0.71–0.78) for predicting 3-year progression to type 2 diabetes. Calibration and decision curve analyses indicated good agreement and net clinical benefit. High-risk individuals exhibited a significantly higher risk of developing type 2 diabetes in both the DPP and DPPOS cohorts (P < 0.001), as well as a 67% increased risk of microvascular complications in DPPOS (P < 0.001), though no significant difference in cardiovascular risk was observed. Significant interactions between treatment and risk group were identified, indicating that high-risk participants benefited more from lifestyle modification and metformin interventions (P for interaction = 0.03 in DPP; P = 0.014 in DPPOS).
Read it at DOI:10.3389/fendo.2026.1746570.
(12 March 2026)
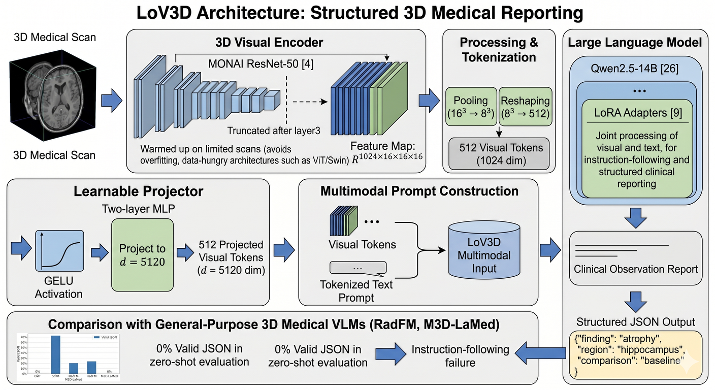 New Preprint LoV3D - Grounding Cognitive Prognosis Reasoning in Longitudinal 3D Brain MRI via Regional Volume Assessments at arXiv:2603.12071.
New Preprint LoV3D - Grounding Cognitive Prognosis Reasoning in Longitudinal 3D Brain MRI via Regional Volume Assessments at arXiv:2603.12071.
Longitudinal brain MRI is essential for characterizing the progression of neurological diseases such as Alzheimer’s disease assessment. However, current deep-learning tools fragment this process - classifiers reduce a scan to a label, volumetric pipelines produce uninterpreted measurements, and vision-language models (VLMs) may generate fluent but potentially hallucinated conclusions. We present LoV3D, a pipeline for training 3D vision-language models, which reads longitudinal T1-weighted brain MRI, produces a region-level anatomical assessment, conducts longitudinal comparison with the prior scan, and finally outputs a three-class diagnosis (Cognitively Normal, Mild Cognitive Impairment, or Dementia) along with a synthesized diagnostic summary. The stepped pipeline grounds the final diagnosis by enforcing label consistency, longitudinal coherence, and biological plausibility, thereby reducing the risks of hallucinations. The training process introduces a clinically-weighted Verifier that scores candidate outputs automatically against normative references derived from standardized volume metrics, driving Direct Preference Optimization without a single human annotation. On a subject-level held-out ADNI test set (479 scans, 258 subjects), LoV3D achieves 93.7% three-class diagnostic accuracy (+34.8% over the no-grounding baseline), 97.2% on two-class diagnosis accuracy (+4% over the SOTA) and 82.6% region-level anatomical classification accuracy (+33.1% over VLM baselines). Zero-shot transfer yields 95.4% on MIRIAD (100% Dementia recall) and 82.9% three-class accuracy on AIBL, confirming high generalizability across sites, scanners, and populations.
Read it at arXiv:2603.12071.
(12 March 2026)
 New Paper Natural language processing for geriatric syndromes - a systematic review of methods, applications, and challenges published at DOI:10.1186/s12911-026-03417-0.
New Paper Natural language processing for geriatric syndromes - a systematic review of methods, applications, and challenges published at DOI:10.1186/s12911-026-03417-0.
Geriatric syndromes (GS) are complex conditions that affect older adults and often require multidisciplinary assessment. Natural language processing (NLP) has emerged as a promising tool for extracting relevant clinical information from unstructured text in electronic health records (EHRs). However, the application of NLP in detecting and monitoring GS remains an evolving area of research. This systematic review explores the role of NLP in the identification and analysis of GS, examining its applications, methodologies, and effectiveness. Furthermore, this review discusses the existing challenges, limitations, and future directions to advance NLP applications in the GS research.
Read it at DOI:10.1186/s12911-026-03417-0.
(25 February 2026)
 Paper published on Lancet Digital Health RareArena - a comprehensive benchmark dataset unveiling the potential of large language models in rare disease diagnosis at 10.1016/j.landig.2025.100953
Paper published on Lancet Digital Health RareArena - a comprehensive benchmark dataset unveiling the potential of large language models in rare disease diagnosis at 10.1016/j.landig.2025.100953
The study introduces RareArena, a new large benchmark dataset designed to improve how artificial intelligence (AI), especially large language models (LLMs), is evaluated for rare disease diagnosis. Medical AI has shown promise in interpreting clinical text and supporting diagnosis, but existing evaluations often rely on small or artificial test sets that don’t reflect the real complexity doctors face. RareArena tackles this gap by collecting thousands of real clinical case reports from PubMed Central and organising them into tasks that mimic real-world clinical problem-solving — such as screening for rare diseases and confirming specific diagnoses from free-text descriptions. The dataset enables systematic comparison of AI models’ abilities to understand medical language and recognise rare conditions, highlighting strengths and limitations in current systems. By providing a realistic testing ground, RareArena aims to accelerate the development of safer, more trustworthy AI tools that can support clinicians in identifying rare diseases earlier and more accurately.
Read it at 10.1016/j.landig.2025.100953.
(3 February 2026)
 Paper published on Radiology Guidelines for Reporting Studies on Large Language Models in Radiology - An International Delphi Expert Survey at https://pubs.rsna.org/doi/full/10.1148/radiol.250913
Paper published on Radiology Guidelines for Reporting Studies on Large Language Models in Radiology - An International Delphi Expert Survey at https://pubs.rsna.org/doi/full/10.1148/radiol.250913
Large language models (LLMs) have transformative potential in radiology, including textual summaries, diagnostic decision support, proofreading, and image analysis. However, the rapid increase in studies investigating these models, along with the lack of standardized LLM-specific reporting practices, affects reproducibility, reliability, and clinical applicability. To address this, reporting guidelines for LLM studies in radiology were developed using a two-step process. First, a systematic review of LLM studies in radiology was conducted across PubMed, IEEE Xplore, and the ACM Digital Library, covering publications between May 2023 and March 2024. Of 511 screened studies, 57 were included to identify relevant aspects for the guidelines. Then, in a Delphi process, 20 international experts developed the final list of items for inclusion. Items consented as relevant were summarized into a structured checklist containing 32 items across six key categories - general information and data input; prompting and fine-tuning; performance metrics; ethics and data transparency; implementation, risks, and limitations; and further/optional aspects. The final FLAIR (Framework for LLM Assessment in Radiology) checklist aims to standardize reporting of LLM studies in radiology, fostering transparency, reproducibility, comparability, and clinical applicability to enhance clinical translation and patient care..
Read it at https://pubs.rsna.org/doi/full/10.1148/radiol.250913.
(16 January 2026)
 Preprint Prevalence of 406 rare diseases by ethnicity and their associated COVID-19 infection burden - A national cross-sectional study of 62.5 million people in England at https://www.medrxiv.org/content/10.64898/2026.01.13.26344068v1
Preprint Prevalence of 406 rare diseases by ethnicity and their associated COVID-19 infection burden - A national cross-sectional study of 62.5 million people in England at https://www.medrxiv.org/content/10.64898/2026.01.13.26344068v1
The burden of the COVID-19 pandemic disproportionately affected individuals with rare diseases. However, the patterning of this risk by ethnicity is complex and runs contrary to general population trends, likely reflecting the deep-seated ethnic disparities in the prevalence of specific RDs. Our foundational map of 406 rare diseases by granular ethnicity is essential for understanding these factors and identifying which specific patient-ethnic subgroups face the greatest intersectional risk.
Read the preprint version at https://www.medrxiv.org/content/10.64898/2026.01.13.26344068v1.