
Why bother using free-text clinical notes for research or patient care?
Alright, in general, we know a significant proportion of the world’s data is in an unstructured format like news articles, Tweets and blogs. Some say 80% of our data is unstructured, while others estimate even more. Unsurprisingly, such phenomena is also observed in health care, such as electronic health records at hospitals.
For example, there is a widely used clinical dataset called MIMIC, which contains 11 years of data from 2 US based intensive care units. It has nearly 60 thousand ICU admissions. On average, there are more than 34 clinical notes for each admission. These notes contain very important information that is never recorded in MIMIC’s structured database, including the drugs people were using at admission, and patient’s past medical history such as whether they had stroke or heart attacks before.
Another example, in 2018, H. Kharrazi and colleagues published a paper which studied the value of fee-text hospital data in identifying conditions that are prevalent in older adults, such as fall and dementia. They produced a very nice chart as shown here. To me, this is a great chart because it delivers a very strong message on how useful and critical free-text data is.
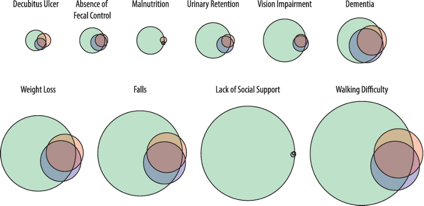
In each of the Venn diagrams,
the top right circle represents claims data (in red color), the bottom right circle represents structured EHR data (in blue), and the left circle represents unstructured free-text EHR data (in green).
In all geriatric syndrome cases, the Venn diagram shows the significance of free-text data. In particular, for “lack of social support” and “malnutrition” cases, the unstructured data constitutes more than 95% of the cases. Even for things like “dementia”, which one might expect good coded data, free-text data still helped to identify a lot of cases that are missing from the structured data.
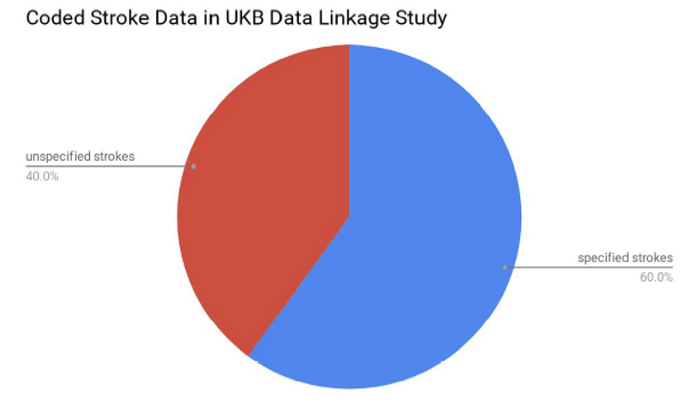
In addition to helping identify cases missed by structured data, free-text data is also very valuable in so-called “deep phenotyping”, that is to identify more specific information of a patient’s condition. Let’s use stroke as an example. In a study published in July 2020, Kristiina and colleagues studied incident stroke cases of UK Biobank cohort in Scotland, which contains 17k people. They found 40% of the cases were coded as unspecified stroke in structured data. We know there are three main subtypes of stroke, they have different causes and hence need to be treated differently. Only knowing unspecified stroke is apparently not very useful. Fortunately, a further study has shown free-text data such as radiology reports can help identify the stroke subtypes of all these 40% cases.
Summary
Ok, till now, I hope I have successfully convinced you that free-text data is important and critical in some scenarios in disease phenotyping.
Written by: Honghan Wu